
WordCloud w kształcie loga na bazie artykułu z Wikipedii

WordCloud, czyli mówiąc w języku naszych ojców chmura słów, to wyjątkowo ciekawa i czasem równie użyteczna forma wizualizacji. Poza tym, że fajnie jest sobie od czasu do czasu "pomalować" logo swojej firmy słowami wybranego artykułu z Wikipedii, to chmury słów mają również swoje zastosowanie w przetwarzaniu danych i komunikacji wyników, z naciskiem na to drugie. W mojej ocenie, chmura słów, to trochę coś w rodzaju mapy drzewa, tyle że w formie wyrazowej. Niemniej, w tym poradniku nauczymy się kilku rzeczy. Po pierwsze, nauczymy się pobierać artykuły z Wikipedii. Po drugie, nauczymy się wizualizować słowa pobranych artykułów w postaci chmur słów. No i po trzecie, nauczymy się nadawać tym chmurom porządany przez nas kształt. Zabierajmy się do pracy!
Pobieranie artykułu z Wikipedii
W pierwszej kolejności zajmiemy się pobraniem wybranych artykułów z Wikipedii i odpowiednim ich przetwarzaniem do formy,
która może być następnie wykorzystana przy tworzeniu chmury słów. Pobierać artykuły możemy na kilka sposobów. Jednym
z nich jest wykorzystanie bilioteki wikipedia-api. Jeżeli nie mamy jej
zainstalowanej, to oczywiście najpierw ją instalujemy.
Zanim pobierzemy jakikolwiek artykuł, to na początek musimy stworzyć łańcuch znaków, który będzie zawierał informacje o przeglądarce, z której korzystamy, naszych danych kontaktowych, a także bibliotece, z której korzystamy do pobierania treści z Wikipedii. Dlaczego? Bo Wikipedia sobie tego życzy. Więcej na temat polityki z tym związanej przeczytacie tutaj.
import wikipediaapi
# Define a custom user agent as per Wikipedia's guidelines
ua_client= "Mozilla/5.0"
ua_contact = "agent.smith@gmail.com"
ua_library = "wikipedia-api/0.6.0"
user_agent = f"{ua_client} ({ua_contact}) {ua_library}"
Następnie, inicjalizujemy obiekt Wikipedia, przekazując do jego konstruktora argument określający wersję językową
Wikipedii, z której będziemy pobierać artykuły, a także argument zawierający stworzony wcześniej łańcuch znaków z
pożądanymi przez Wikipedię informacjami.
# Define the language and user agent
lang = wikipediaapi.Wikipedia(language="en", user_agent=user_agent)
Chcąc, żeby wszystko było jasne i klarowne definiuję zmienną article_title, którą przypisuję do łańcucha znaków będącego
kropka w kropkę tytułem artykułu, który chcemy pobrać z Wikipedii - pamiętamy również o wybranym języku. To znaczy, jeżeli
ustawiliśmy language="en", to API założy, że chcemy pobierać artykuły z wersji anglojęzycznej Wikipedii.
# Define the title of the Wikipedia article
article_title = "Data science"
Ostatecznie pobieramy całą stronę i ekstrachujemy z niej tekst.
# Get the Wikipedia page for the specified article
page = lang.page(article_title)
# Get the text content of the article
article_text = page.text
I voila, tekst artykułu mamy pobrany. Występuje on obecnie w formie pojedynczego łańcucha znaków, z którego musimy teraz wyektrachować słowa i pozbyć się innych znaków, takich jak przecinki, kropki, apostrofy i tego typu inne rzeczy. Użyjemy w tym celu pakietu do przetwarzania języka naturalnego o nazwie NLTK, który pomoże nam podzielić łańcuch znaków na pojedyncze elementy w interesujący nas sposób. Chcemy mianowicie oddzielić słowa od wszystkiego tego, co słowami nie jest.
...
import nltk
from nltk.tokenize import word_tokenize
...
# Tokenize the article text into words
nltk.download("punkt") # Download NLTK tokenizer data if not already downloaded
words = word_tokenize(article_text)
Oczywiście jeżeli nie macie tego pakietu, to go najpierw zainstalujćie 😉 Niemniej, w linijce nltk.download("punkt"),
NLTK łączy się ze swoim serwerem danych i pobiera zbiór danych "punkt" na lokalny komputer, jeśli jeszcze go nie ma.
Ten zbiór danych jest stosunkowo niewielki i zawiera informacje o tokenizacji zdań i słów. Czyli innymi słowy pozwala
tokenizerowi tokenizować, czyli po prostu ciąć tekst na słowa (mówiąc w skrócie). Jeżeli więc sobie teraz wyświetlimy
zawartość zmiennej words, to zobaczymy w konsoli coś takiego:
['Data', 'science', 'is', 'an', 'interdisciplinary', 'academic', 'field', 'that', 'uses', 'statistics', ',' ...
Ostatnim krokiem jest pozbycie się z tej listy wszystkich elementów nie będących słowami i zapisanie listy słów do pliku
CSV w pojedynczej kolumnie. Możemy do tego celu wykorzystać bibliotekę pandas i obiekt typu DataFrame.
...
import pandas as pd
...
# Create a DataFrame with a single column "Words"
df = pd.DataFrame({"Words": words})
# Filter rows that contain words
filtered_df = df[df['Words'].str.contains(r'\w', na=False)]
# Save filtered DataFrame as CSV file
filtered_df.to_csv("wikipedia_data_science.csv", index=False)
Tadam! W ten sposób udało nam się stworzyć input do chmury słów. Cały skrypt wygląda następująco:
import wikipediaapi
import nltk
from nltk.tokenize import word_tokenize
import pandas as pd
# Define a custom user agent as per Wikipedia's guidelines
ua_client= "Mozilla/5.0"
ua_contact = "johnsmith@gmail.com"
ua_library = "wikipedia-api/0.6.0"
user_agent = f"{ua_client} ({ua_contact}) {ua_library}"
# Define the language and user agent
lang = wikipediaapi.Wikipedia(language="en", user_agent=user_agent)
# Define the title of the Wikipedia article
article_title = "Data science"
# Get the Wikipedia page for the specified article
page = lang.page(article_title)
# Get the text content of the article
article_text = page.text
# Tokenize the article text into words
nltk.download("punkt") # Download NLTK tokenizer data if not already downloaded
words = word_tokenize(article_text)
# Create a DataFrame with a single column "Words"
df = pd.DataFrame({"Words": words})
# Display the DataFrame
print(df.head()) # Display the first few rows of the DataFrame
print(df)
# Filter rows that contain words
filtered_df = df[df['Words'].str.contains(r'\w', na=False)]
# Save filtered DataFrame as CSV file
filtered_df.to_csv("wikipedia_data_science.csv", index=False)
Autopromocja 🌱
Zachęcamy do zainteresowania się naszymi szkoleniami:
- Programowanie w języku Python dla średniozaawansowanych
- Fundamenty przetwarzania i analizy danych w języku SQL
- Fundamenty programowania w języku Python
- Fundamenty języka Java
Wizualizacja chmury słów
Do tworzenia chmur słów wykorzystamy bibliotekę WordCloud. Zanim jednak przejdziemy
do implementacji i omawiania rozwiązania stanowiącego trzon tej opowieści, to przyjrzyjmy się w jaki sposób, najprostszy sposób,
możemy wykorzystać wspomniany przed chwilą pakiet WordCloud. Będziemy do tego potrzebowali zarówno tego pakietu,
jak i pakieto matplotlib.
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# Sample text data
text = ("Zanim jednak przejdziemy do implementacji "
"i omawiania rozwiązania stanowiącego trzon "
"tej opowieści, to przyjrzyjmy się w jaki sposób, "
"najprostszy sposób, możemy wykorzystać wspomniany "
"przed chwilą pakiet WordCloud.")
# Generate the word cloud
wordcloud = WordCloud().generate(text)
# Display the word cloud using Matplotlib
plt.imshow(wordcloud)
# Show the plot
plt.show()
I po odpaleniu skryptu dostaniemy w rezultacie coś takiego:

Jak więc widzimy nawet w tak podstawowej formie chmura słów jest wyjątkowo ciekawym sposobem wizualizacji danych tekstowych. Nam zależy jednak na rozwiązaniu o wiele bardziej ciekawym, choć niestety to przełoży się na odrobinę dłuższy i bardziej skomplikowany kod. Ale zostańcie ze mną do końca bo warto 😉
No dobrze. Kod z przykładu podstawowego wykorzystania WordCloud kasujemy i piszemy coś takiego:
# User params
csv_file = 'wikipedia_data_science.csv' # Specify the CSV file to read data from
png_file = 'logo_text_mask.png' # Specify the PNG file to read mask from.
W pierwszej linii definiuję nazwę pliku CSV, w którym przechowywane są słowa z artykułu pobranego z Wikipedii.
W drugiej linii natomiast zamieszczam nazwę pliku PNG, który wykorzystamy do utworzenia chmury słów w obrębie liter
loga danetyk. Plik ten wygląda tak:
Pewnie tego nie widać, ale grafika ta posiada białe tło oraz czarne litery. Ważne jest jednak to, aby tło miało wszystkie wartości RGB równe 255, natomiast dla liter, aby wartości RGB były równe 0. Jest ważne o tyle, że wykorzystanie tej grafiki jako maski spowoduje, że podczas tworzenia chmury słów ta przyjmie rozmiar maski, ale wypełni słowami jedynie miejsca, na których maska jest czarna.
Przejdźmy dalej. Teraz musimy wgrać plik CSV z wykorzystaniem biblioteki pandas, przekształcić kolumnę wyrazów
do formy listy, po czym zliczyć wystąpienia wszystkich słów z osobna, bo, niespodzianka, skorzystamy z alternatywnego
sposobu generowania chmurek.
import pandas as pd
from collections import Counter
# Load a CSV file with single words spread across consecutive rows of a single column
df = pd.read_csv(csv_file)
# Convert 'Words' column to a list
words = df['Words'].tolist()
# Convert all words to lowercase and count word frequencies
words_frequencies = dict(Counter(word.lower() for word in words))
Supcio. Teraz możemy stworzyć maskę na bazie pokazanego wcześniej pliku graficznego:
...
from PIL import Image
import numpy as np
...
# Load a mask image
mask = np.array(Image.open(png_file))
No i teraz już tylko wystarczy wygenerować chmurkę:
...
from wordcloud import WordCloud
import matplotlib.pyplot as plt
...
# Create the WordCloud object with custom parameters
wordcloud = WordCloud(mask=mask)
# Generate the word cloud using word frequencies or relevance values
wordcloud.generate_from_frequencies(words_frequencies)
# Show word cloud
plt.imshow(wordcloud, interpolation="bilinear")
plt.show()
Jednak gdy teraz uruchomimy tak napisany skrypt...
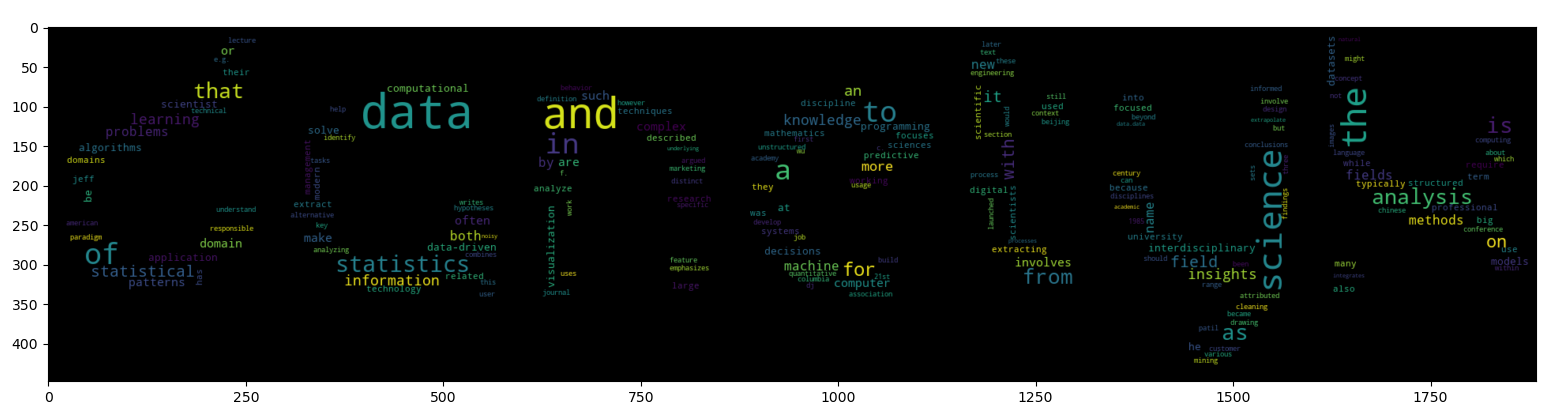
...to niestety efekt nie należy do tych najwyższych lotów 🙃 W tym celu musimy "trochę" dopieścić ten skrypt, przy czym całość wygląda nastepująco:
import pandas as pd
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import random
from collections import Counter
# User params
csv_file = 'wikipedia_data_science.csv' # Specify the CSV file to read data from
png_file = 'logo_text_mask.png' # Specify the PNG file to read mask from.
# Mask image should have white background RGB(255,255,255) and black mask region RGB(0,0,0).
# The DPI of the cloud depends of the PNG file size!
use_desired_color = True # Set to True if you want to use a specific color for words
cloud_desired_color = "rgb(0, 0, 0)" # Define the desired color in RGB format
use_random_color = True # Set to True if you want to use random colors for words
# Define a dictionary for random RGB color ranges
crc = {
'r': (0, 255), # Range of red component from 0 to 255
'g': (0, 255), # Range of green component from 0 to 255
'b': (0, 255) # Range of blue component from 0 to 255
}
cloud_width = 1800 # Width of the WordCloud image
cloud_height = 500 # Height of the WordCloud image
repeat_words = True # Set to True to allow word repetitions in the WordCloud
background_color = 'white' # Set background color for the WordCloud
# Load a CSV file with single words spread across consecutive rows of a single column
df = pd.read_csv(csv_file)
# Convert 'Words' column to a list
words = df['Words'].tolist()
# Convert all words to lowercase and count word frequencies
words_frequencies = dict(Counter(word.lower() for word in words))
# Load a mask image
mask = np.array(Image.open(png_file))
# Define a custom color functions
def desired_color(word, font_size, position, orientation, font_path, random_state):
return cloud_desired_color
def random_color(word, font_size, position, orientation, font_path, random_state):
# Generate a random RGB color
r = random.randint(crc['r'][0], crc['r'][1])
g = random.randint(crc['g'][0], crc['g'][1])
b = random.randint(crc['b'][0], crc['b'][1])
return f"rgb({r}, {g}, {b})"
if use_desired_color:
color_func = desired_color
elif use_random_color:
color_func = random_color
else:
color_func = None
# Create the WordCloud object with custom parameters
wordcloud = WordCloud(
background_color=background_color,
repeat=repeat_words,
width=cloud_width,
height=cloud_height,
mask=mask,
color_func=color_func
)
# Generate the word cloud using word frequencies or relevance values
wordcloud.generate_from_frequencies(words_frequencies)
plt.figure(figsize=(15, 10))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.tight_layout()
plt.show()
Efekt wywołania tego skryptu jest następujący:

Dotychczasowy kod wzbogaciłem o kilka kluczowych elementów. Po pierwsze dodałem kilka dodatkowych parametrów na jego początku,
które mogą być ustawiane przez użytkownika. Mowa tutaj konkretnie o use_desired_color, cloud_desired_color, use_random_color,
crc, cloud_width, cloud_height, repeat_words i background_color. Ustawienie use_desired_color na True spowoduje,
że słowa w chmurze przyjmą kolor zdefiniowany w cloud_desired_color. Z kolei ustawienie use_random_color na True spowoduje,
że dla każdego słowa zostanie przypisany losowy kolor z zakresu RGB określonego w crc. Ostatecznie, jeżeli ustawimy zmienną
repeat_words na True, to dopuścimy w ten sposób powtarzanie tych samych słów podczas generowania chmury. Pozostałych zmiennych
chyba nie muszę już objaśniać 😉
Podsumowanie
No i cóż, tak oto przedstawia się temat generowania chmur ze słów wyekstrachowanych z pobranych artykułów z Wikipedii.
Warto w tym miejscu wspomnieć, że konstruktor klasy WordCloud przyjmuje wiele bardzo ciekawych argumentów. Pierwszym
z brzegu jest colormap, który przyjmuje nazwy skal kolorystycznych zdefiniowanych w pakiecie matplotlib.
Tutaj znajdziecie pełną listę tych skal. Jeżeli jednak
chcemy z tych skal skorzystać, to musimy pamiętać o rezygnacji z argumentu color_func - albo jedno, albo drugie.
Ogólnie zachęcam do zapoznania się z pozostałymi parametrami klasy WordCloud. Do następngo! 👋

Materiały
Wszystkie materiały wykorzystane w tym poradniku znajdziecie na GitHubie: https://github.com/danetykpl/danetykpl/tree/main/materialy/poradniki/poradnik_1